Why is this question important? According to a 2014 article, suicide rates in the Pacific Islands are some of the highest in the world. In countries like Samoa, Guam, and Micronesia, suicide rates are double the global average with youth rates even higher.
I decided to look at the World Health Organization's Global School Based Health Survey taken in the Western Pacific countries, most of them in the 2010s (China's was taken in 2003). The purpose in looking at those surveys is to see if I can predict whether a child would be suicidal or not.
There is a question in the survey that asks if a child has seriously considered attempting suicide in the past 12 months in the survey. In most surveys, there are two related questions which I did not keep as my features (they would highly bias what I am trying to predict). But, I used all the other survey questions to see if I could classify whether a child has seriously considered attempting suicide or not.
In addition to the survey, I gathered information about the country itself, such as GDP and population. I combined my data tables using some SQL.
(I used Tableau to create all of the charts I will be showing.)
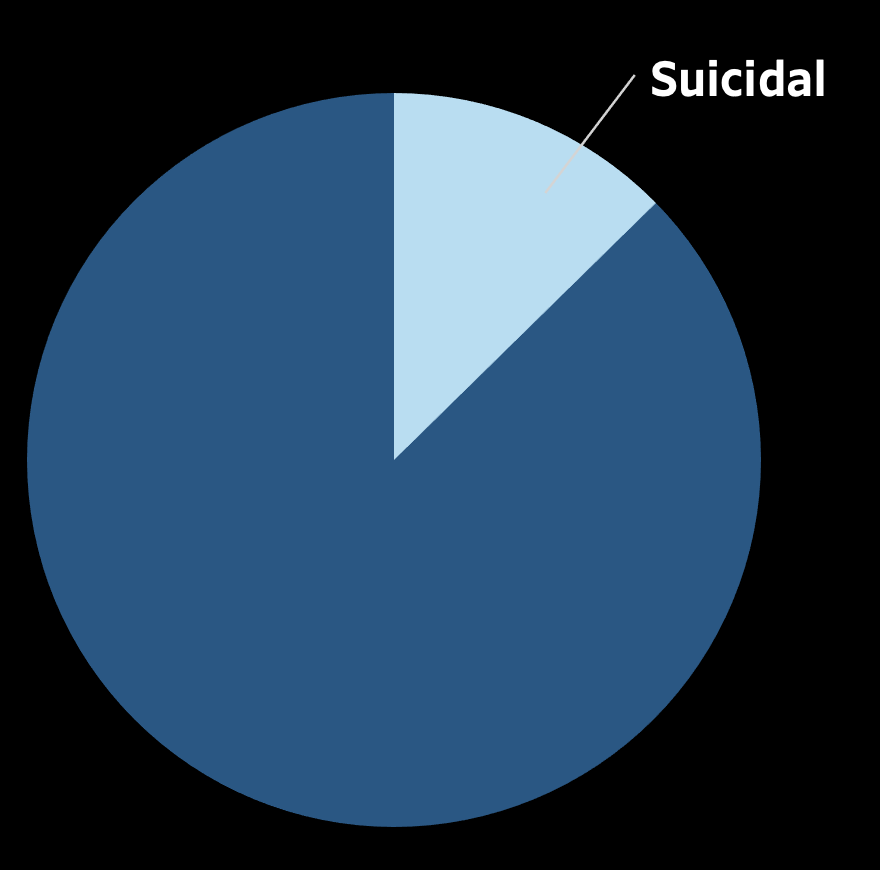
According to the survey data, about 13% of children are suicidal in the surveyed Western Pacific countries.
This imbalance caused me to change my class-weights in my logistic regression model. It was a 5:1 class weight situation, where the suicidal class weighed 5 times as much as the non-suicidal class.
I used an F1 metric, weighing both precision and recall equally to evaluate my model. I received an F1 score of .42 on a hold out set using logistic regression.
I later decided to use XGBoost to potentially improve my F1 score. I did not use class weights, but did decrease the threshold for my positive class to .19 and received an F1 score of .44.
Actually, recall is slightly higher when using logistic regression than XGBoost. I should have chosen logistic regression as my main model, or should have used an F-beta metric to weigh recall more (since it is better to catch all of the suicidal kids even though some may not really be suicidal than to not catch all of the at-risk kids). But, I chose XGBoost as my main model and looked at the feature importance.
I found some very interesting correlations. One top feature in both my XGBoost model and one that gave a lot of signal in my logistic regression model is the loneliness factor and insomnia factor.
Suicidal Children are 3x as Likely to Have Experienced Extreme or Moderate Loneliness

Suicidal Children are 3x as Likely to Have Lost Sleep over Excessive Worrying

Suicidal Children are 3x as Likely to Have Been Bullied


Where are these suicidal children located?
It turns out the top three countries with the highest percentage of suicidal children (according to the survey) is in islands.

Is it a coincidence that Samoa is in the top 3 high risk countries? I'm not too surprised, since there is an article that mentions Samoa having very high youth suicide rates.
But, why the islands?
The article mentions that lack of economic opportunity among the youth may be the cause, but the data also paints a slightly different angle of the phenomena.
So, the takeaways:
Top conditions that are related to children to become suicidal are loneliness, bullying, worrying and insomnia and perhaps cigarette use.
Other considerations may be the child's gender and the perception on how much their parents understand their problems. Also, population and a country's colonial history shows up as important features somehow.
At the end of the day, it is hard to predict whether a child is suicidal or not from just health survey data, but it does show some interesting trends.


